How has DeepSeek affected the AI Market for investors?

Portfolio Manager, Global Team

Portfolio Manager, Global Team

What happened with DeepSeek?
A breakthrough from Chinese AI company DeepSeek sent shockwaves through equity markets in late January, wiping out nearly a trillion dollars in US technology value and causing Nvidia to lose close to $600bn in market cap, the largest single-day loss in history. Whilst equities have since recouped some of these losses, the news raised questions about the future trajectory of AI and caused investors to weigh up several potential investment implications.
What is DeepSeek?
DeepSeek is an AI start-up founded in 2023 by Liang Wenfeng, employing just c.150 people and backed by ‘High-Flyer’, a Chinese quant hedge fund. DeepSeek previously released a base Large Language Model (LLM), called V3, in December 2024, but the big news that rocked markets came towards the end of January when it published its latest ‘R1’ reasoning model. This model took a big step forward from a technical perspective, displaying performance on par with the cutting-edge US models, but (supposedly) costing just a fraction of the amount to train.
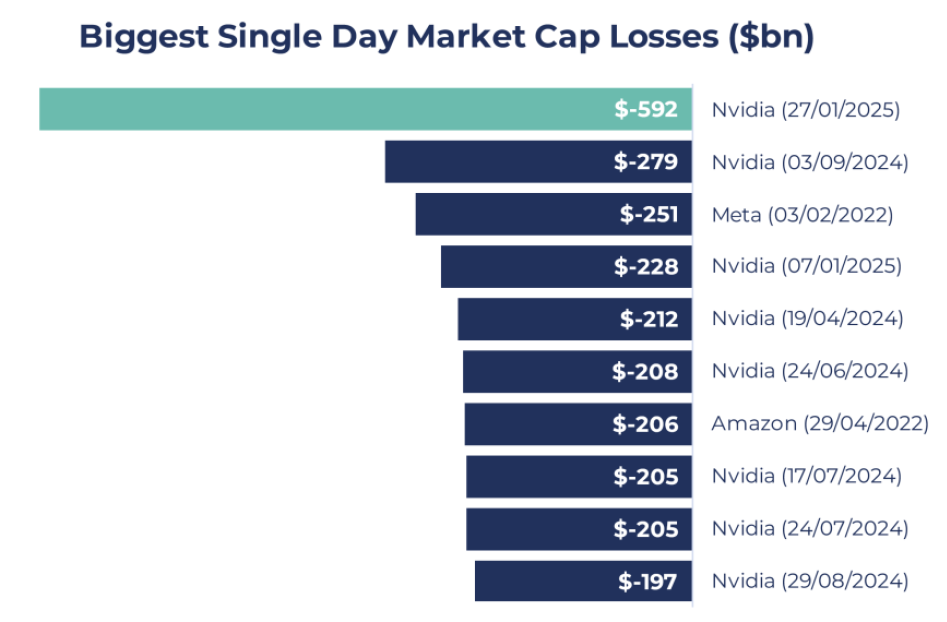
Source: Bloomberg; as of 31st January 2025
How was DeepSeek V3 cheaper than US competitors?
DeepSeek claims its base model (V3) was trained on a mere 2,000 H800 Nvidia chips at a cost of just $5.6m, an order of magnitude less than current leading US models. DeepSeek achieved this by using efficient algorithms, optimised hardware, strategic graphical processing unit (GPU) allocation, and an AI training technique called Mixture of Experts that substantially improves computational efficiency. Some speculation suggests DeepSeek used more compute than they claim, possibly even export-restricted H100s, but there is no hard evidence for this. Nonetheless, it’s important to stress that the $5.6m figure has been slightly misunderstood, as it simply refers to the cost of the final model training run (and doesn’t include the cost of buying the compute cluster, prior research costs, staff salaries, data processing, etc). Even so, the model was still far cheaper than the existing US competitors.
DeepSeek also released an updated R1 ‘reasoning model’ in January – a distilled, more efficient version of its V3 base model. In this process, knowledge from the complex V3 is transferred to a smaller model that retains key functionality but lowers computational demands. While DeepSeek did not disclose R1's cost, it is also believed to be an order of magnitude cheaper than its counterpart’s reasoning model (OpenAI’s o1). Crucially, DeepSeek models are all open-sourced, granting developers and researchers free access to modify and use them. Currently, only Meta (Llama) and Alibaba (Qwen) offer open-source models, while most leading providers (OpenAI, Gemini, Anthropic, Perplexity AI) remain closed-source and behind a paywall.
What was the breakthrough that made DeepSeek so impactful?
DeepSeek addressed a significant AI challenge: enabling models to reason step-by-step. Traditionally, LLMs have been trained on a very compute-intensive process called supervised learning, where models are fed immense quantities of labelled data and then match inputs to correctly labelled outputs. In contrast, DeepSeek’s reasoning model was accomplished using a technique called reinforcement learning, where responses are fine-tuned by rewarding accurate outputs and penalising mistakes. This approach mimics human reasoning by breaking tasks into intuitive, process-driven steps and giving feedback at each step of the way. In simplified terms, it’s like teaching someone how to write intuitively via feedback instead of getting them to memorise every single word ever written.
Although OpenAI introduced a reasoning model in September 2024, DeepSeek became only the second firm to do so, matching OpenAI’s performance (see chart below) at a fraction of the cost. It also surprised many that a Chinese competitor had made such a big leap forward in LLM technology, when it was widely held that China was years behind the US.
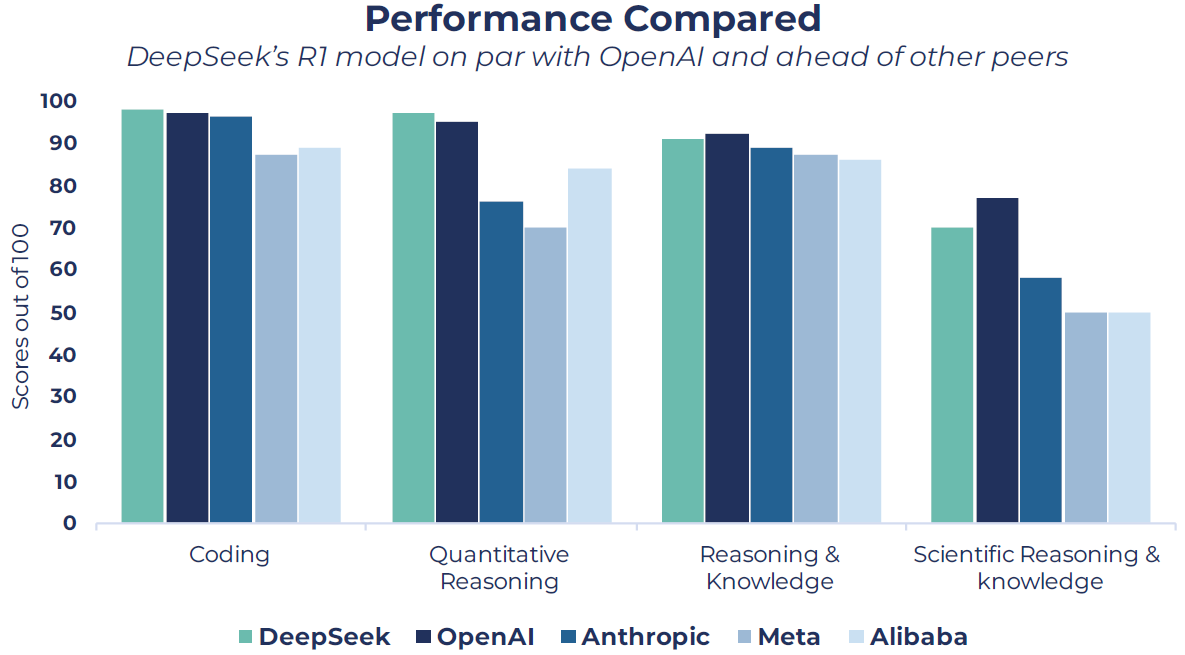
Source: Guinness Global Investors, Artificial Analysis; as of 31st January 2025
Note: Models used OpenAI (o1), Alibaba (Qwen 2.5 72B), Meta (Llama 3.1 405B), Anthropic (Claude 3.5). Tests used are HumanEval, MATH-500, MMLU, GPQA Diamond
What are the implications for AI companies?
The impact on the broader AI theme – and for investors – hinges on the distinction between training and inference.
Training is the process where an AI model learns by analysing massive amounts of data and adjusting its internal parameters, while inferencing refers to the trained model applying that knowledge to make real-time and real-world predictions on new, unseen data. If DeepSeek has pioneered a way to create lower-cost models, increased training competition from upstarts could emerge. Because of the huge demand for the latest chips used in cutting-edge AI training (primarily Nvidia GPUs), the waiting list can often extend to many months. If LLMs can now be trained using fewer GPUs and at a lower cost, this may enable a wider range of market participants to access these chips, leading to greater model creation and perhaps even the commoditisation of LLMs. This is especially the case if open-source models (like DeepSeek) can provide similar performance without sitting behind a closed-source paywall. It may be the case that companies will differentiate themselves at the application-layer (that which is built on top of LLMs), instead of the pure LLM technology itself.
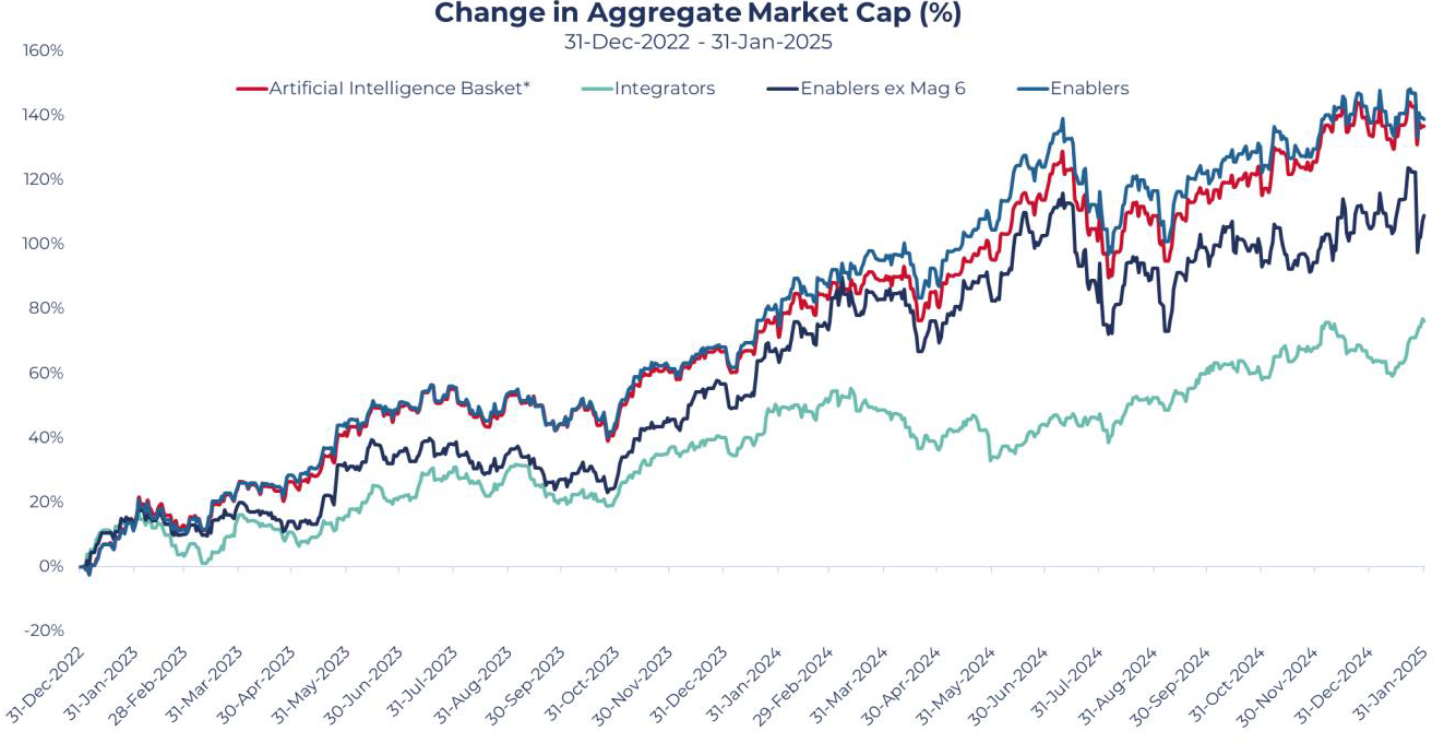
Source: MSCI, Bloomberg; as of 31st January 2025
*Artificial Intelligence Basket is a selection of stocks that Guinness Global Investors believe is most exposed to the AI theme.
Lower training costs and more efficient models might accelerate the shift from training to inference, a process that is already underway. Inference is widely believed to have a far larger total addressable market over the long term as it includes a wider range of use cases. These include asking an LLM simple questions to getting autonomous vehicles to process live data in real time. LLMs that are less power-hungry will be able to operate on a greater number of so-called ‘edge devices’ (devices that process data near the source such as phones, cars, or wearable accessories) and will aid the move to inference. As a result, we may see value creation shift away from the ‘AI enablers’ (those that provide the foundational AI infrastructure) towards the ‘AI integrators’ (those that provide software, applications and services built on top of that infrastructure). The chart above shows the January performance of these two groups and in particular the sharp divergence after the DeepSeek announcement. While the initial market reaction suggests Integrators may emerge as a beneficiary of cheaper and more efficient models, there is clearly still a wide range of opportunities at many stages of the AI value chain.
How does this affect AI spending?
Despite the DeepSeek news, hyperscalers continue to spend heavily on AI infrastructure (at least for the time being). Microsoft are leading the charge, forecasting $80bn of capital expenditure (capex) in 2025, with Meta calling for $60-$65bn this year, and Oracle, Softbank, and OpenAI recently announcing long-term investments of up to $500bn via the Stargate Project. This capex is generally split between compute (e.g. buying Nvidia GPUs or Broadcom ASICs) and infrastructure (the physical data centres that store, process, and distribute the data). If training and inference are becoming more efficient, then some argue that hyperscalers will reduce their overall capex spend and right-size their infrastructure footprint. However, we believe it is more likely that a huge uptake in inferencing will more than offset any potential fall in training (see above). This view has been corroborated by recent earnings releases which indicate a continued commitment to large-scale capex spend:
Meta CEO Mark Zuckerberg: “We continue to believe heavily investing in the company’s AI infrastructure will be a strategic advantage… It’s possible that we’ll learn otherwise at some point, but I just think it’s way too early to call that.”
Microsoft CEO Satya Nadella commented on their balanced approach to building infrastructure: “We are building a pretty fungible fleet … and making sure that there’s the right balance between training and inference.” He also noted that their CapEx spend will be enduring: “You don't want to buy too much of anything at one time... you want to continuously upgrade the fleet, modernise the fleet, age the fleet and, at the end of the day, have the right ratio [of capex to demand].”
Moreover, whilst DeepSeek does point to a step change in the efficiency of models, there has been an ongoing optimisation cycle in the world of LLMs. Initially, firms were in a rush to get models to market with no focus on cost. However, over the past year, OpenAI has refined its models and optimised training cost (GPT4 cost less than GPT3.5 which in turn cost less than GPT3). Some estimates suggest that algorithmic progress improves fourfold each year, meaning that with each passing year, achieving the same capabilities requires only a quarter of the compute previously needed. The market was already aware of this optimisation cycle and yet the hyperscalers continue to increase their capex (see chart below). This should give investors some solace (or concern) that large-scale capex is likely to continue for the foreseeable future, even if there is some rationalisation of spend at the margins.
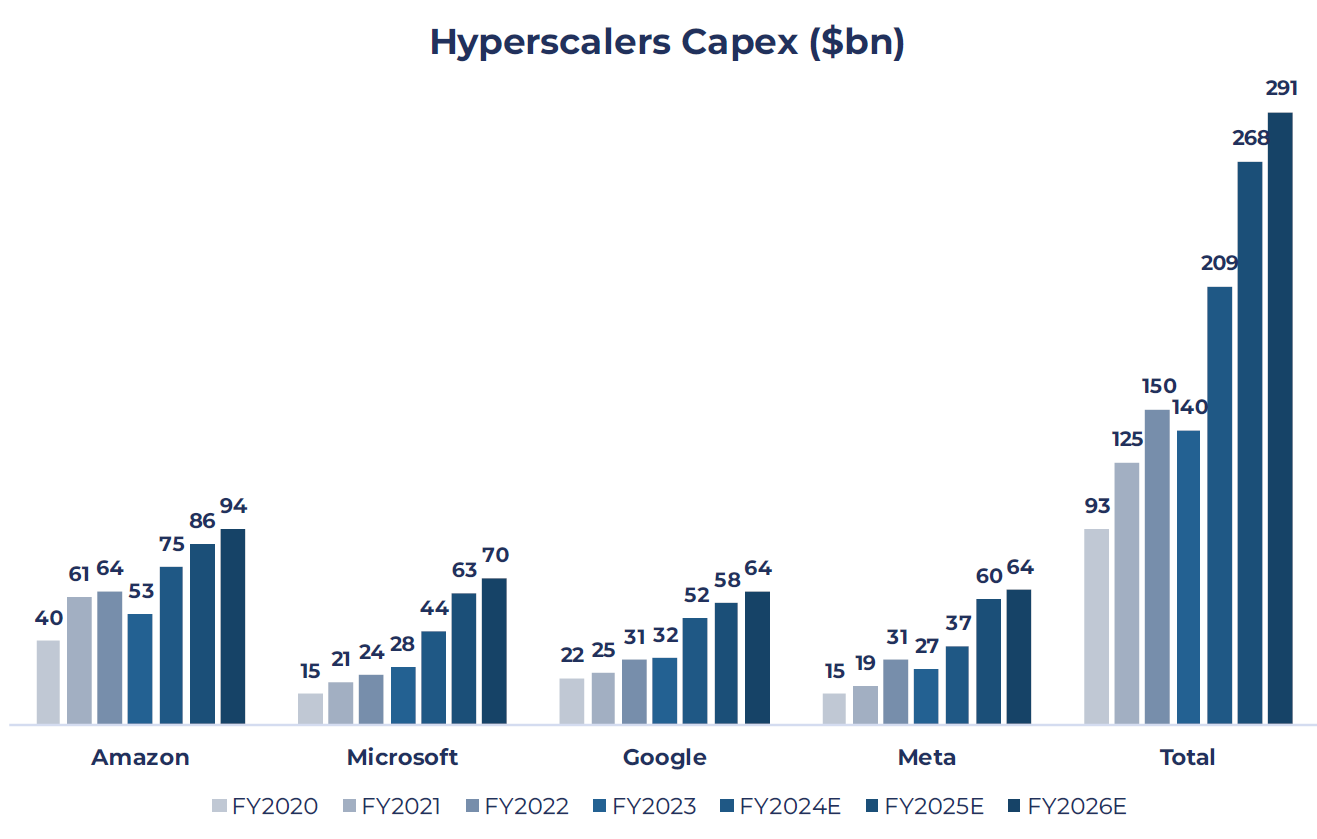
Source: Bloomberg; as of 31st January 2025
Note: Data takes consensus estimates until the end of January 2025. Expectations have shifted at time of writing given earnings reports in early February
What does this mean for AI in the long term?
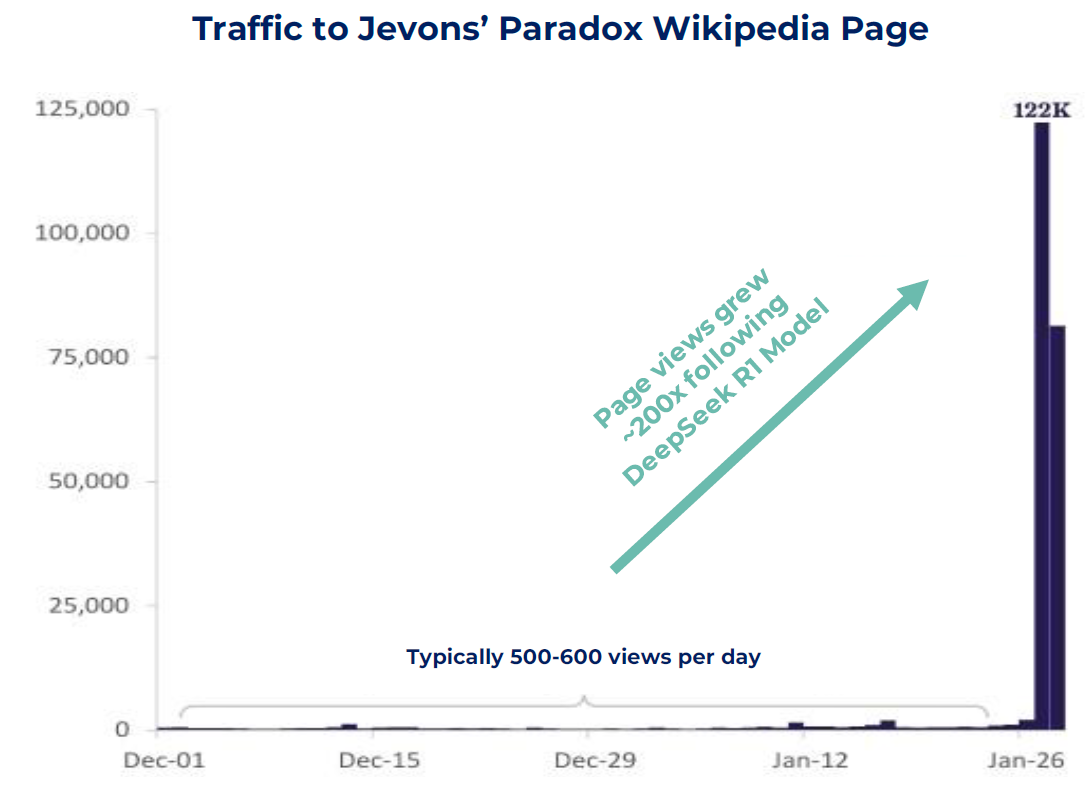
Sources: Chartr, PageViews Analysis, SemiAnalysis as of 31st January 2025
The long-term implications of the DeepSeek model are far from certain and, given the pace of AI developments, will likely play out in ways that can’t be foreseen. This has allowed both pessimists and optimists to enlist the DeepSeek news in support of their positions. For those that thought the AI theme was overhyped, the market news over January reinforced their viewpoint. Conversely, many have sought to strengthen the bull case by citing Jevons’ Paradox, which states that increased efficiency in resource use can lead to higher overall consumption (not a reduction) because lower costs will drive more use cases and therefore greater overall demand. With regards to compute, the argument here is that more efficient AI models will lead to a cheaper cost of use, and therefore more organisations can run AI (largely through inferencing), which will lead to a steeper adoption curve. Looking back over 50 years and further, ever since the advent of the microprocessor, there has never been a lack of demand for compute. More powerful machines (and therefore more abundant compute) have always been used to innovate and benefit the end consumer across a wide range of use cases. The chart above shows the growing popularity in Jevons’ Paradox, and this may yet continue to hold true.
How did the Market react to DeepSeek?
Who were the winners and losers?
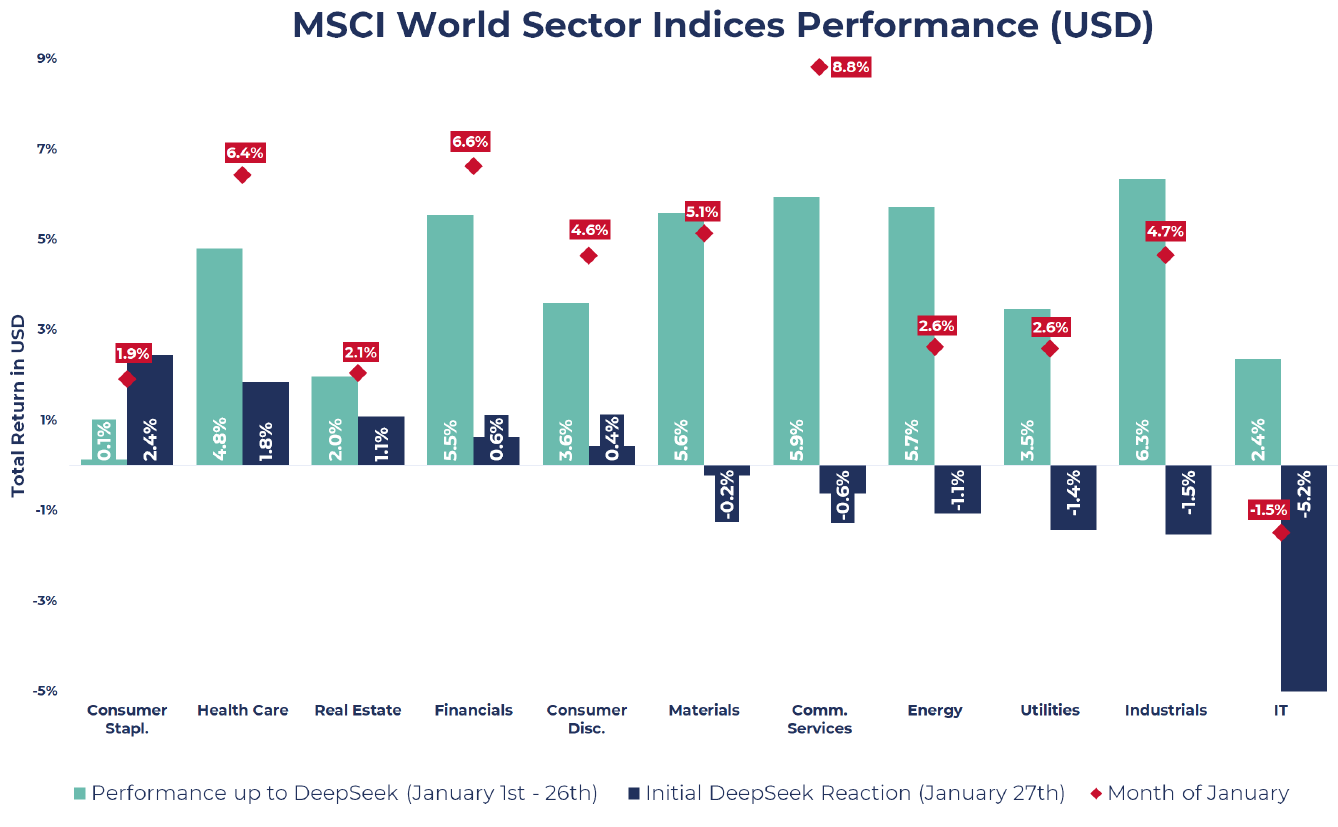
Source: Bloomberg, MSCI, Guinness Global Investors
The chart above outlines MSCI World performance over January until the DeepSeek announcement (in green), the market reaction on the day of the R1 model release (in blue), and January performance in red. As the chart depicts, stocks generally performed well over January up until the release of DeepSeek R1, with broad-based gains and positive returns from all sectors. However, on the DeepSeek announcement, performance was much more varied. Sectors like IT, Industrials, Utilities and Energy, those that include many of the AI Enablers, were the most negatively impacted as investors weighed up the implications of lower training costs on companies involved in the data centre build-out.
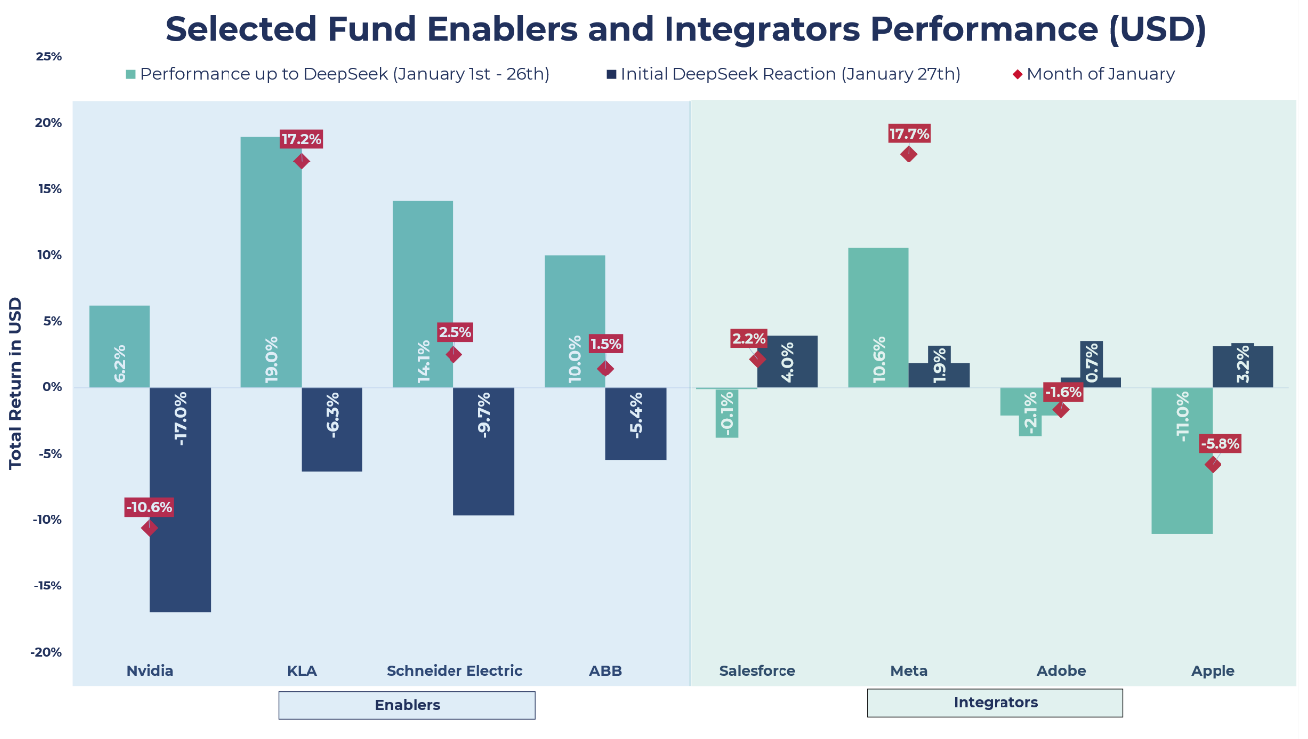
Source: Guinness Global Investors, Bloomberg
How did Enablers react?
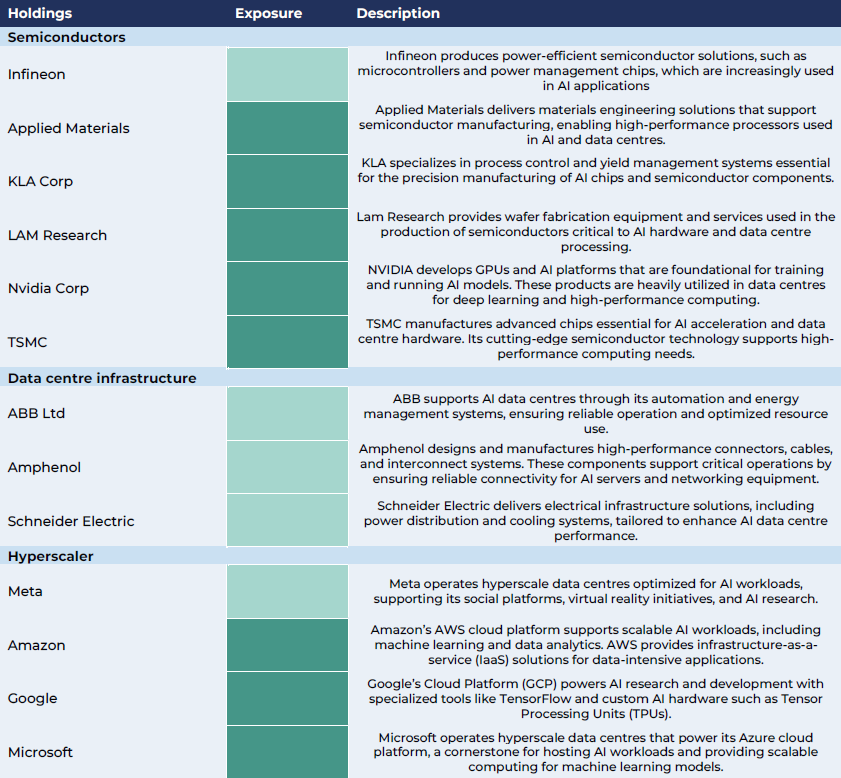
Source: Guinness Global Investors
On 27th Jan, Nvidia suffered the largest single-day market capitalisation loss in history, wiping almost $600bn from its market value, as market participants assessed the potential impacts of lower training costs on future compute demand, and more specifically, GPU demand. Considering that in recent earnings calls by some of the hyperscalers we have seen a recommitment to previously guided 2025 capex numbers, a big cancellation of GPU Nvidia orders seems unlikely in the short term. In the medium term, a possible scenario is the emergence and shift towards sleeker, more efficient AI models that don’t rely on AI GPU clusters of such massive scale. However, other industry experts argue a potential consequence of fewer entry barriers to training models could be more competition and use cases, and with that, more inference demand. Interestingly, Nvidia is not only extremely well positioned to serve the AI training market, but it is also the largest inference platform in the world, as roughly 40% of the company’s revenue stems from inferencing. Nvidia CEO Jensen Huang mentioned during the Q3 2025 earnings call that “We’re seeing inference really starting to scale up for our company.” Therefore, we believe the release of DeepSeek R1 does not change our thesis in Nvidia, and we feel optimistic about its future performance despite its impressive rally over the last two years. Our flexible but disciplined portfolio management approach of ‘letting our winners run’ beyond the c.3% position weight has allowed us to generate substantial gains from Nvidia and at the same time crystallise some of those gains by trimming the position six times since 2023.
Another AI Enabler company that saw a big drop on the 27th Jan (-6.3% USD) is KLA, one of the largest semiconductor wafer fabrication equipment (WFE) manufacturers in the world, as investors weighed up the possibility of lower demand for advanced chips leading to reduced orders for the process and control equipment machines that KLA provides to the semiconductor manufacturers. Despite this share price drop, KLA still managed to secure a spot as the second-best performer of the Fund during the month (+17.2% USD), as a strong set of quarterly results and positive 2025 outlook, which matched peers Lam Research (also held in the Fund) and ASML (not held), helped dissipate investor fears about AI demand.
The ramifications of the DeepSeek R1 release also led to a sharp one-day price decline in some of the AI Enabler Industrials stocks held the Fund, such as Schneider Electric (-9.7% USD) and ABB (-5.4% USD), although both finished the month in positive territory. Potentially, lower demand for compute could negatively affect both companies, as their data centre revenue is partly a function of compute demand and the services and products required to ensure efficient functioning of data centres. For reference, Schneider Electric’s revenue exposure to data centre is 25%, whereas ABB’s is 10% as of 2023. We remain optimistic that their exposure to the data centre build-out will continue to boost their top-line growth while providing a diversified source of revenue to their high-quality businesses.
How did Integrators react?

Source: Company Data, Guinness Global Investors
As described above, many AI Enablers’ share prices initially reacted negatively to the release of DeepSeek. On the other hand, we found that, broadly, AI Integrators’ share prices reacted positively, including Salesforce (+4% USD), Meta (+1.9% USD), Adobe (+0.7% USD) and Apple (+3.2% USD). The likely explanation is that the market is factoring in declining AI training costs, which could drive the commoditisation of LLMs and shift companies' focus toward the implementation layer built on top of them. By being closer to the end customers, these companies can embed AI into their data and products, potentially increasing monetisation as the value proposition of their services and products rises. Note that while Meta is investing heavily to develop its own AI infrastructure, like many of the enablers, we view the firm as more of an ‘Integrator’ given that it is integrating AI to develop its core operations. For example, the firm is using AI to drive engagement in its Family of Apps and thus generate further advertising revenues.
While companies at various stages of the AI value chain reacted differently to the release of DeepSeek R1, their initial share price reaction is hardly a prediction of what the future might hold. We believe we are still at the early stages of the AI trend and remain optimistic about our holdings’ potential to extract value across all parts of the AI value chain.
Are we in an AI bubble?
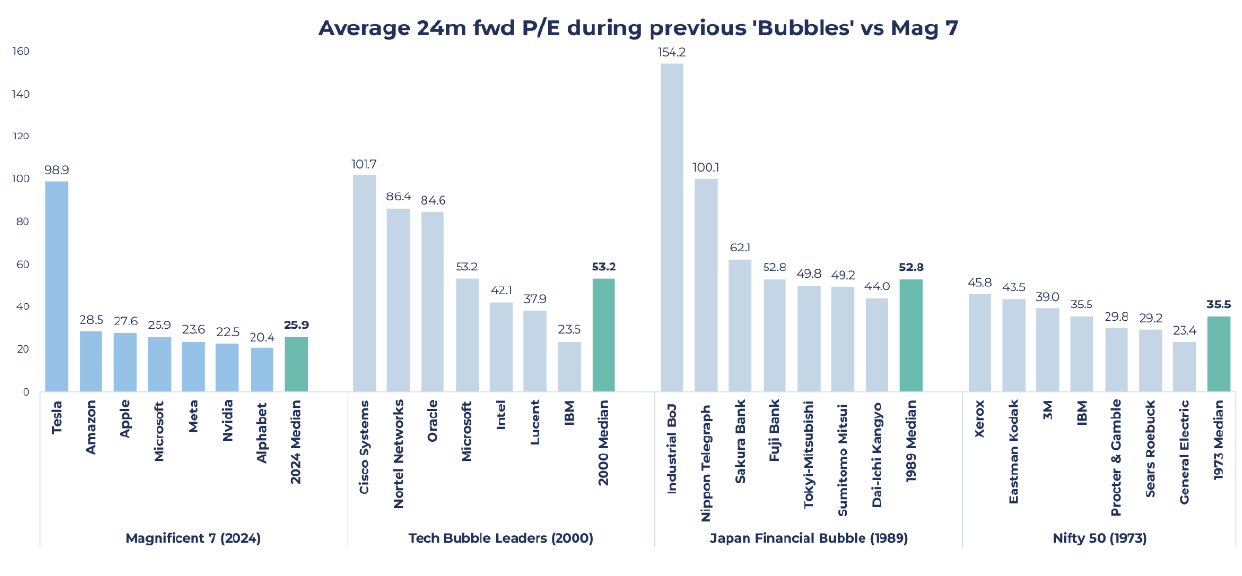
Source: Guinness Global Investors, Goldman Sachs, Bloomberg
The chart above shows the average 24 months forward price/earnings (P/E) ratio for some of the more highly valued companies during previous bubbles and the current Magnificent 7 as of end of 2024. Excluding Tesla, the only company among the Magnificent 7 not held in the Fund, Magnificent 7 valuations remain significantly lower than those seen in bubbles of the past. The Magnificent 7 median P/E ratio (24 months forward) is 25.9x, compared to 35.5x from the Nifty 50, 52.8x from the Japan Financial Bubble and 53.2x from the 2000 Tech Bubble. There is a considerable difference between past bubbles and the current Magnificent 7 valuations, which reflect profitable growth expectations.
We continue to monitor the rapidly evolving AI landscape and the implications for both enablers and integrators. While the Guinness Global Innovators Fund has clearly benefited from exposure to AI, we find it interesting to note that this exposure has not increased in the last two years, and AI is only our third-largest theme by weight. Our approach allows us to have exposure to this attractive secular growth theme while remaining diversified. Additionally, the portfolio's equally weighted structure ensures no single position becomes overly dominant, providing balance in a rapidly evolving market.


